Setting up a local large language model (LLM) like GPT-3 can be challenging due to the significant computational resources and infrastructure required. But we also know that it is important for privacy, low latency and sensitive financials applications. We would need a large installed base of AI-ready systems, as well as the right developer tools to tune and optimize AI models on our system.
Large Language Model for local Documents and Video
For the purpose of this demo, we will use free tool provided by Nvidia i.e. Chat with RTX. It supports various file formats, including text, pdf, doc/docx, and xml. We simply need to point the application at the folder containing your files and it’ll load them into the library in a matter of seconds. Additionally, we can provide the url of a YouTube playlist and the app will load the transcriptions of the videos in the playlist, enabling us to query the content they cover. We will see the examples in a while.
Hardware Requirements
- High-performance GPUs e.g. RTX 30 or 40 series are supported by the app. NVIDIA RTX GPUs are capable of running a broad range of applications at the highest performance — unlock the full potential of generative AI on PCs. Tensor Cores in these GPUs dramatically speed AI performance across the most demanding applications for work and play.
- RAM: 16 GB or higher
- Storage: 70 GB including the setup
Software Requirements
- OS: Windows 10 or higher
- Chat with RTX app. File size is 35GB. However, during installation, additional resources would be downloaded and total size including setup would be around 70 GB
Installing Chat with RTX based on Mistral
After downloading and unzipping the file, start the setup and go with default options as follows. Please note the setup would take time as it downloads a additional resources. The application uses Mistral 7B INT4 AI model. In order to avoid issues, you may need to choose folder name and path without spaces.
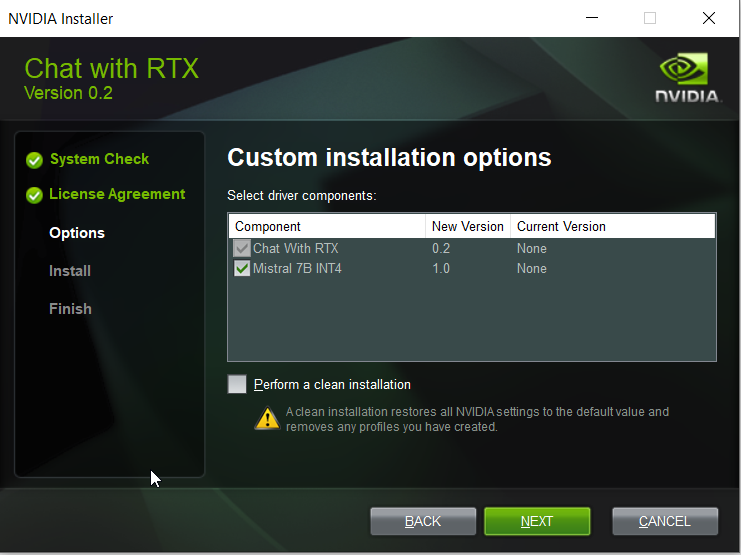
Let’s Chat with Large Language Model
After installation, we will now test the app. For sample document, we have used a mother user manual in pdf as an input and asked different questions. See how easily it extracts required information without us to go through the complete user manual document.
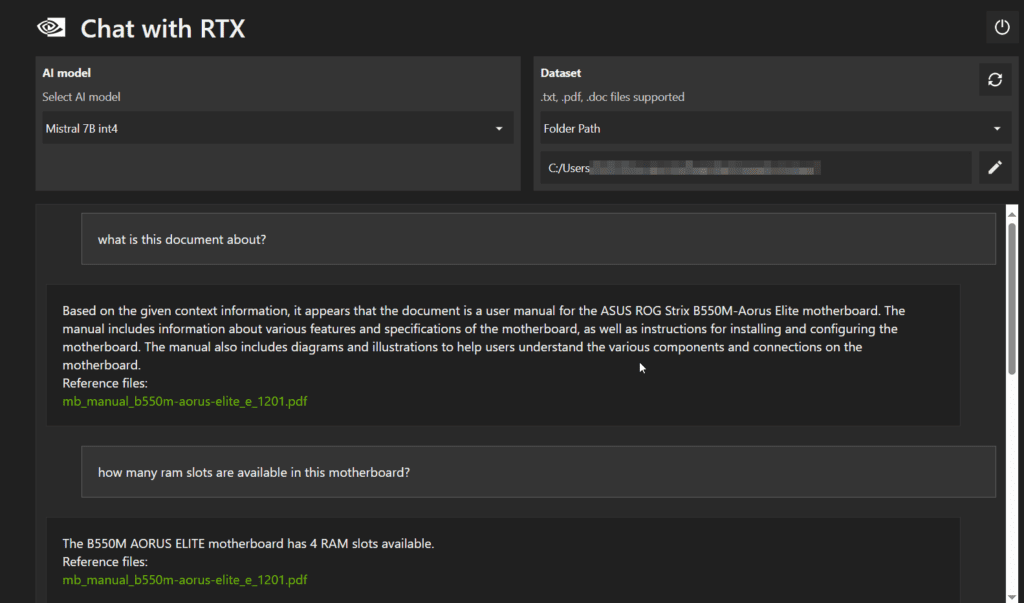
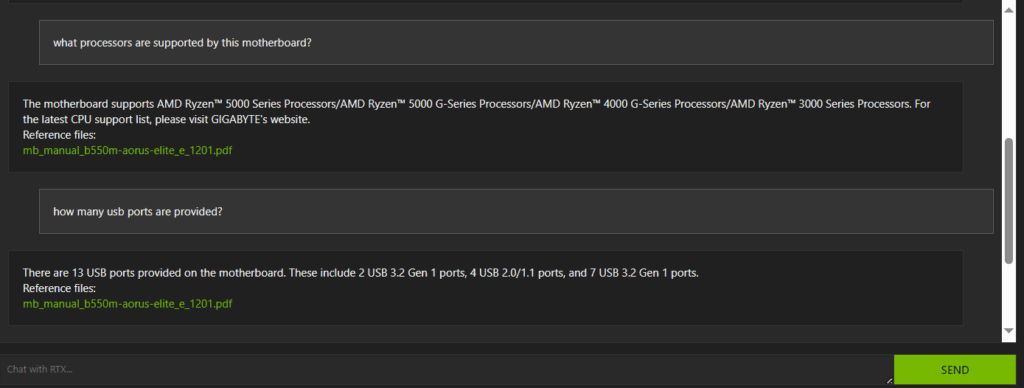
We have asked some more technical questions and see it is convenient to get the information in less than a minute!
Similarly, we can enter the URL (e.g. https://www.youtube.com/watch?v=TJUkVlh08WY) of a YouTube playlist and the app will load the transcriptions enabling us to query the content they cover.
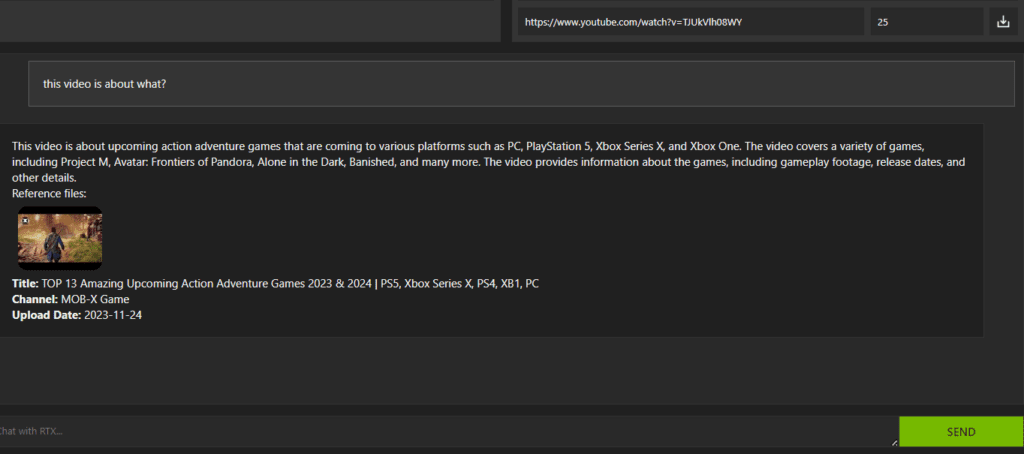
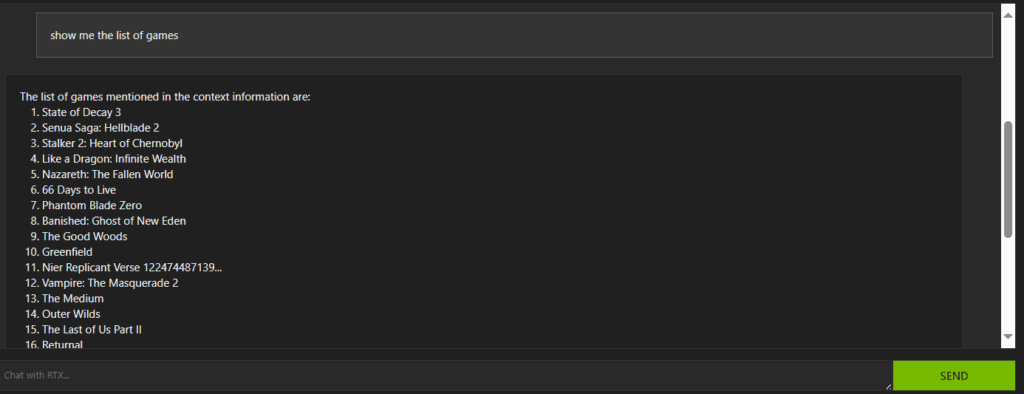
Rather than going through whole, we can directly ask for the list of games covered in the video.
Remember that working with large language models is a complex task that requires knowledge of deep learning concepts, access to powerful hardware, and adherence to ethical guidelines. Always stay informed about the latest developments in the field and follow best practices.